If you’re the person in a dental group responsible for vetting software — the IT lead, the security reviewer, the integration architect — most “AI for dentistry” pitches give you nothing to evaluate. They describe outcomes, not systems. This piece is the opposite: the engineering behind ELVA’s Practice Brain, written for someone who needs to understand the dental AI architecture before signing off on it, not just hear what it does. Where a claim has a limit, you’ll find the limit stated.
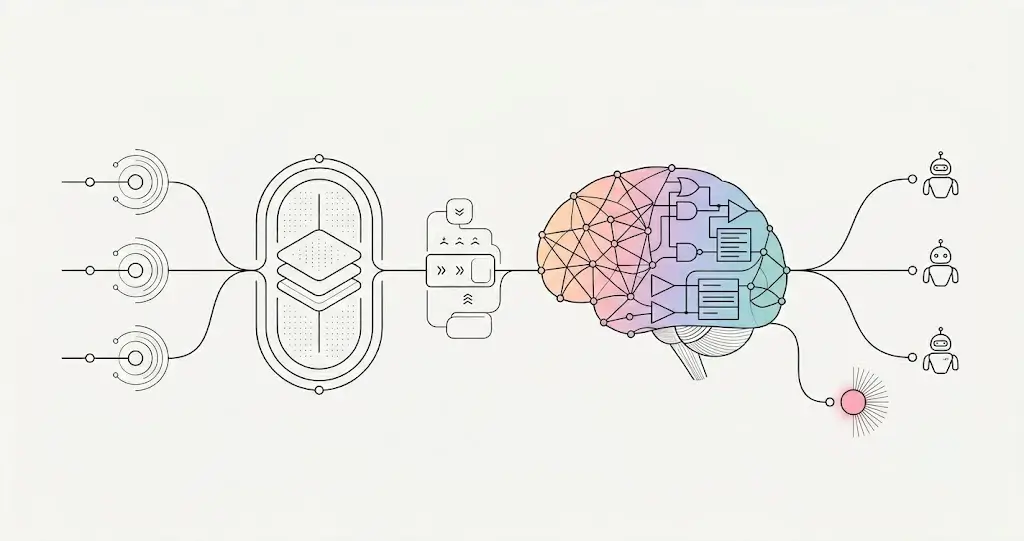
The thesis up front: ELVA isn’t a language model with a dental prompt. It’s a neural-symbolic, multi-agent system grounded in a specific practice’s real data and bound by explicit rules, with knowledge acquisition, governance, autonomy, and integration each engineered as a distinct subsystem. Here’s how each works.
Why not a pure language model
A general-purpose LLM is fluent but ungrounded. It can discuss dentistry in the abstract but can’t reliably state what a specific practice produced yesterday or how a specific payer adjudicates a code — and when it doesn’t know, it generates a plausible answer rather than stopping. For a regulated, rule-dense domain where most operational answers are determined rather than matters of opinion, that failure mode is disqualifying. The engineering requirement isn’t a better model; it’s an architecture that retrieves and applies rather than approximates.
Neural-symbolic core. The Brain pairs a neural subsystem (deep learning — natural-language understanding and pattern recognition) with a symbolic subsystem (rule-based reasoning applied deterministically). The neural side proposes; the symbolic side disposes. This is the central architectural decision: pattern-recognition alone is too loose for compliance-bearing decisions, and hard rules alone are too brittle for the messiness of real practice data. The pairing is what yields both flexibility and correctness.
Multi-agent system, one shared memory
The Brain isn’t a single model. It’s a multi-agent system — specialized agents for billing, scheduling, communication, and so on — that each handle a domain but operate on one shared context. The architecturally important property is the shared memory: the scheduling agent operates on the same knowledge and live data the billing agent does, so an action in one domain is immediately coherent in another without re-entry or sync gaps. This is the difference between a system and a set of integrated point tools that each hold their own state and reconcile after the fact.
Knowledge acquisition: the two-source engine
The hardest engineering problem in practice-specific AI isn’t reasoning — it’s knowledge acquisition: getting what’s true about one practice into a structured, current, trustworthy form. ELVA extracts from two fundamentally different sources and reconciles them.
Source 1 — stated knowledge (interviews). An AI-led conversational interview with the people who run the practice. The engineering choice worth noting: answers are stored two ways. The raw natural-language answer is preserved and used directly as model context (an LLM interprets “the doctor should NOT discuss cost” more faithfully from the original phrasing than from any key-value reduction of it), while a separate extraction step derives structured data from the same answer to power validation and a confirmation interface. The interview routes questions by role, generates follow-ups from prior answers, and detects conflicts when two staff describe the same process differently.
Source 2 — observed knowledge (practice data). In parallel, ELVA analyzes the practice’s own systems for actual behavior. The fully-built instance is insurance: it ingests historical claim adjudications (what the payer actually did) and published payer/state/ADA documents (what the payer says it does) and reconciles them.
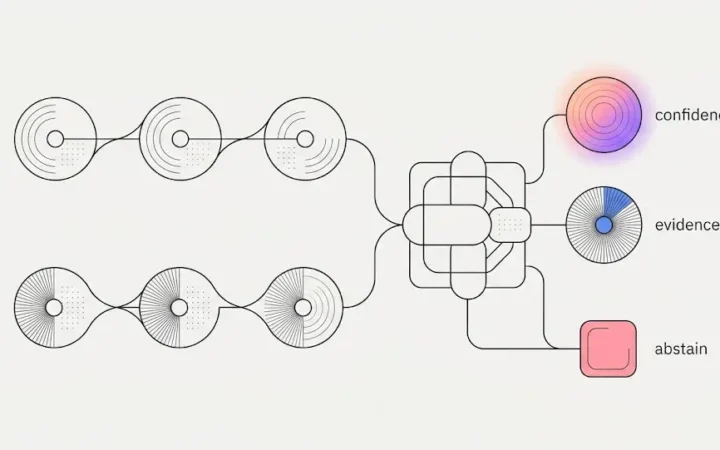
Under the hood — derived rules and document extraction. On the behavioral side: every adjudicated claim is normalized into a structured observation, observations are pooled into payer-plan-procedure cells, and a rule is derived per cell where evidence supports one — gated by a confidence threshold that strengthens as more claims corroborate it, and validated against a holdout set. On the document side: published policies are parsed, extracted into candidate rules each grounded to the exact source excerpt, and passed through an automated judge (plus human review where needed) before activation. Two evidence types, one engine — and the same proposes/disposes discipline as everywhere else in the system.
Reconciliation as signal. When stated and observed disagree — “we always verify secondary insurance” vs. data showing it happens 60% of the time — ELVA doesn’t silently pick a winner. It surfaces the gap as a high-value signal. For a technical evaluator, the important property is that the system is engineered to expose disagreement between evidence sources rather than collapse it.
Governance: scoped rules and wildcard-aware precedence
Knowledge in a multi-location org isn’t flat. The Brain holds three knowledge bases — Corporate, Local, Universal — and resolves which applies per decision via a precedence engine. Every rule is scoped along dimensions (organization, location, payer, plan, procedure, and so on); lookups resolve by precedence, where a more specific scope overrides a broader one and the configured ordering (e.g., Corporate → Local → Universal) determines which applicable rule governs. Setting Corporate-over-Local for one class of decision and Local-over-Corporate for another is native behavior of the inheritance model, not a workaround. This is the same wildcard-aware precedence engine ELVA’s insurance module already runs in production — the governance layer generalizes it to the practice’s full operating knowledge.
Autonomy: supervised, with escalation as a designed function
The Brain acts, but within bounds. Because the domain is rule-dense, a large share of cases are rule-determined and handled autonomously; cases that are ambiguous, low-confidence, or outside what’s rule-determined are escalated to a human. The engineering point for an evaluator: escalation is a first-class designed behavior, not a fallback. The same proposes/disposes principle that governs answers governs actions — no answer is preferred over a wrong answer. The autonomous share is high because the domain is rule-dense, and ELVA frames it honestly as the routine majority today, increasing as the system matures — not as full autonomy.
Integration: a layer above the PMS, with honestly-tiered depth
The Brain isn’t a PMS and doesn’t replace one. An integration layer connects to each practice’s existing system and normalizes its data into the Brain’s shared context; the governance and reasoning layers sit above that integration layer and are identical regardless of the PMS underneath. This is what makes the operating standard portable across a heterogeneous group.
The honest limit, stated plainly because a technical evaluator will and should probe it: the operating-standard layer is genuinely PMS-independent — your rules apply uniformly because they live in the Brain, not the PMS — but integration depth is tiered per system. How much ELVA reads from and writes back to Open Dental versus Dentrix Ascend versus on-premise Dentrix Classic is genuinely different to engineer, and is handled per system. The portable standard is uniform; the integration depth is not. That distinction is the accurate version of the claim.
Security and data governance
Three properties are architectural, not policy promises. Isolation: a practice’s (and an organization’s) data is private — ELVA does not learn one organization’s knowledge into another’s, and patient data is not used to train public models. Where cross-practice generalization occurs, it is strictly de-identified behavioral patterns (e.g., warm-starting a new practice’s insurance rules), never private operating knowledge and nothing that identifies a practice or patient. Scoped access: role- and location-based access control, enforced by the system, so a provider sees their own data, a location doesn’t see another’s, and nothing crosses between practices unless intended. Auditability: actions are logged with the rule they acted on, so behavior is traceable after the fact — the basis for demonstrating, not merely asserting, that a policy was followed.
The proof it’s real: production today
The strongest evidence for a technical evaluator is that this isn’t a roadmap. ELVA already runs this exact architecture in one domain in production: the insurance engine acquires coverage knowledge from observed claim behavior and stated payer policy, reconciles them, scopes them by precedence, gates them before activation, and applies them deterministically. The Practice Brain is that proven pattern — two-source acquisition, reconciliation, scoped precedence, gated activation, neural-symbolic application — generalized across the whole practice. When you evaluate the rest, you’re evaluating the generalization of a system already running, not a hypothesis.
For the conceptual foundations behind this, the two companion pieces are the architecture of the Practice Brain and how it learns a specific practice. To see it in product form, ELVA’s AI Brain.
Frequently Asked Questions
Is ELVA a large language model with a dental prompt?
No. ELVA is a neural-symbolic system: a neural subsystem for language understanding and pattern recognition paired with a symbolic subsystem that applies explicit, scoped rules deterministically. The neural side proposes; the symbolic side disposes. This grounds answers in a practice’s real data and binds them with real rules, rather than generating plausible text.
How does ELVA integrate with our existing PMS?
Through an integration layer that connects to each PMS and normalizes its data into the Brain’s shared context; the governance and reasoning layers sit above it, identical regardless of PMS. Honestly stated: the operating-standard layer is PMS-independent, but integration depth (how much ELVA reads and writes per system) is tiered per PMS and handled per system.
How are rules governed across multiple locations?
Via three scoped knowledge bases (Corporate, Local, Universal) resolved by a wildcard-aware precedence engine. Every rule is scoped (organization, location, payer, plan, procedure); a more specific scope overrides a broader one, and you set precedence ordering per class of decision. It’s the same precedence engine ELVA’s insurance module runs in production.
What are ELVA’s data-isolation and audit guarantees?
Data is isolated per organization — ELVA doesn’t learn one organization’s knowledge into another’s, and patient data isn’t used to train public models; cross-practice generalization is strictly de-identified behavioral patterns. Access is role- and location-scoped, and actions are logged with the rule they acted on, so behavior is auditable after the fact.
Is this architecture actually in production or just planned?
In production. ELVA’s insurance engine already runs the full pattern — two-source knowledge acquisition, reconciliation, scoped precedence, gated activation, deterministic application. The Practice Brain generalizes that proven, running system across the whole practice rather than introducing an untested design.
Evaluate the architecture in depth. Start with the architecture of the Practice Brain and how it learns your practice, or see ELVA’s AI Brain.